Trek's File Storage System with Amazon S3


This blogpost is a modified version of an internal Trek document. You can view the internal document here.
At Trek, our goal is to make trip planning as smooth and efficient as possible. To achieve this, we decided to integrate AWS S3 for storing images and files, allowing users to upload photos and other media easily. In this blog post, we’ll walk you through our integration process, the challenges we faced, and how we overcame them.
Why AWS S3?
AWS S3 (Simple Storage Service) provides scalable object storage, making it an ideal choice for our needs. It offers:
- Reliable and durable storage.
- Scalability to handle large amounts of data.
- Integration with other AWS services.
- Secure access control and management.
- Overview of the Integration
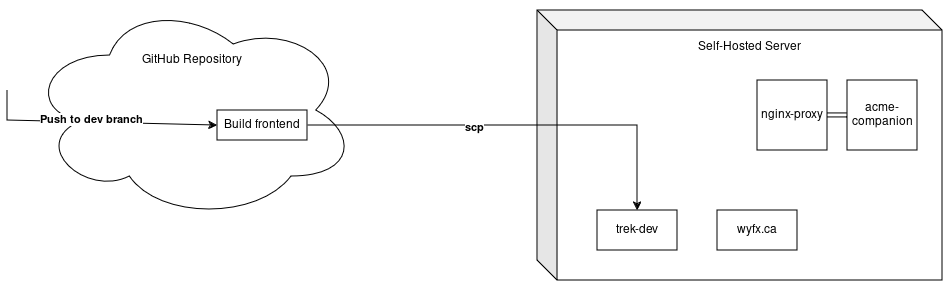
The integration of AWS S3 in Trek is handled entirely by our backend Express server to ensure security and simplicity. Here’s a high-level overview of the data flow when a user uploads an image:
- User Uploads Image: The user uploads an image through the frontend.
- Backend Processing: The image is sent to the backend server, which handles the upload to S3.
- S3 Storage: The image is stored in an S3 bucket.
- MongoDB Logging: Metadata about the uploaded image is logged in our MongoDB database.
- S3 Pricing Considerations
While AWS offers a Free Tier with the following limits:
- 5GB of S3 storage.
- 20,000 GET requests.
- 2,000 PUT, COPY, POST, or LIST requests.
- 100GB of data transfer out per month.
It’s essential to monitor usage to avoid unexpected costs. We learned the hard way when a private, empty S3 bucket unexpectedly incurred a $1300 charge. Always monitor your S3 usage and set budget alerts to avoid surprises.
Setting Up AWS Access
To interact with AWS S3, we use an IAM user, trek-s3-user, which has the necessary permissions to upload files. The credentials are stored in environment variables for security:
ATLAS_URI="..."
AWS_ACCESS_KEY_ID=your_access_key_id
AWS_SECRET_ACCESS_KEY=your_secret_access_key
AWS_REGION=us-east-2
S3_BUCKET_NAME=cpsc-455-trek
These keys are used by our backend server to authenticate requests to AWS S3.
MongoDB Schema for S3 Files
We keep track of the files stored in S3 using a MongoDB collection called S3Files. Here’s the schema:
- _id: Auto-generated unique ID.
- key: S3 object key.
- bucket: S3 bucket name.
- url: URL of the stored object.
- upload_by: User ID of the uploader.
- upload_time: Timestamp of the upload.
Backend Validation Before Upload
To ensure that only appropriate files are uploaded, we perform several validations on the backend:
- File Type: Verify the file type being uploaded.
- File Size: Check if the file size is within acceptable limits.
- Upload Frequency: Limit the number of files a user can upload within a specific period.
Middleware for S3 & MongoDB
Our backend uses Express middlewares to handle the upload and logging process:
- Auth0 Middleware: Verifies the JWT token and appends user information to the request.
- S3 Middleware: Uploads the image to S3 and appends the metadata to the request.
Here’s an example of the S3 uploading middleware:
import { upload } from './s3/upload';
app.post('/test/upload', upload.array('photos', 3), function (err, req, res) {
if (err) {
// handle upload error
}
res.send('Successfully uploaded ' + (req.files?.length ?? 0) + ' files!');
});
If an error occurs during the upload, it’s passed to the callback function, allowing for proper error handling.
Conclusion
Integrating AWS S3 into Trek has enhanced our ability to handle user-uploaded images efficiently and securely. By leveraging AWS S3’s scalable storage and integrating it with our backend, we’ve ensured that our users have a seamless experience when planning their trips. We hope our journey and insights help you in your own integration projects.
Stay tuned for more updates and technical deep dives from the Trekkers team!